
At Skybrud.dk where I work, most of our solutions have some sort of integration with external data. For a majority of these solutions, it makes most sense to either save the data in a local database or as a file on disk. But in other cases, it make most sense to store the external data in Umbraco as content item - eg. if an editor later should be able to edit the imported data - or add additional data to it.
For instance when making an online shop, we might want to import product data from an external system. So for the sake of this article, let's assume that our fictional online shop gets product data from an external source.
To keep things simple - and let you play around with changing the source data - the product data is saved in a JSON file.
Creating a plan of action
Like most things in Umbraco, there isn't a single way to accomplish something like this. For this article, I will go through the following steps:
- Getting the products from the external source
- Determining whether products should be added or updated
- Populating the properties in Umbraco
- Minimizing the data saved in the local database
- Setting up a scheduled task for importing the products at a certain interval
While I may not be able to explain everything in this article, I've included an Umbraco test solution which you can download, and get it up running using Visual Studio, IIS or similar. If you're using Visual Studio, you should be to just press CTRL + F5 ;)
The test solution is based on The Starter Kit. However when you boot up the solution, you might see that I have deleted all products that normally comes with the starter kit. Instead you'll have the run the import job (more about this later) to get any products.
For the test solution, the login for the backoffice is skrift@skrift.io for the username and SkriftRocks1234 for the password.
Getting the products from the external source
If you pull down the GitHub repository, you will find the JSON file I described earlier at ~/App_Data/Products.json - or you can grab the contents from here. Normally you would pull the products from a URL or similar, but with a local file, you can try and change of the property values, and then run the importer again.
For parsing the JSON file, we'll be using the widely used JSON.net and create models that represents the products and other data involved. The models can be found in this folder.
With the models from the repository, loading and parsing the JSON file could look something like:
// Map the full path to the JSON file on disk
string path = IOHelper.MapPath("~/App_Data/Products.json");
// Read the raw contents of the file
string contents = System.IO.File.ReadAllText(path);
// Parse the raw JSON into a list of products
ProductList productList = JsonConvert.Deserialize<ProductList>(contents);As you can see from the models, I've decorated the properties with JsonProperty attributes to match the JSON. While it's convention in .NET to use Pascal casing (eg. Products), the properties in the JSON are using camel casing (eg. products). We can control the parsing using these JsonProperty attributes (which is part of JSON.net).
However, out in the real world, you might end up with some JSON that requires a bit more than just JsonProperty attributes. JSON.net is still the way to got, but this part is out of the scope of this article.
Determining whether products should be added or updated
In the demo solution, all products are added under a single container node, and each product has an external ID we can use to check whether a product already has been imported in Umbraco. As such, we can get all products from Umbraco's content cache:
// Get a reference the container node
IPublishedContent container = Umbraco.TypedContent(1234);
// Get all children (products) from the container
Enumerable<IPublishedContent> children = container.Children;The Children property returns an instance of Enumerable<IPublishedContent>. If we just stick with this type (which we shouldn't — I'll come back to that), the updated code could look something like:
// Make the full path of the JSON file
string path = IOHelper.MapPath("~/App_Data/ExternalProducts.json");
// Read the raw contents of the file
string contents = System.IO.File.ReadAllText(path);
// Parse the raw JSON into a list of products
ProductList list = JsonConvert.Deserialize<ProductList>(contents);
// Get a reference the container node
IPublishedContent container = Umbraco.TypedContent(1234);
// Get all children (products) from the container
Enumerable<IPublishedContent> children = container.Children;
// Iterate through each product from the JSON file
foreach (Product product in list.Products) {
// Has the product already been imported?
bool exists = children.Any(x => x.GetPropertyValue<string>("externalId") == product.Id);
if (exists) {
// update product
} else {
// add product
}
}Using the right tool for the job
Choosing the right collection
As mentioned earlier, we really shouldn't cross reference an instance of Enumerable<IPublishedContent> like I did in the example above. Let's say we have hundreds or thousands of products — both in the JSON file and in Umbraco. The amount of products in the JSON file could be denoted N, while the amount of products already imported in Umbraco could be denoted M.
With the foreach loop and the use of the Any method as shown above, we could potentially make up to N * M iterations. So if we have 100 products in the JSON file, and they all have been imported in Umbraco, that would be 10000 iterations. 1000 products would be 1000000 iterations. This is bad for performance, as the amount of iterations will grow exponentially as our shop gets more products.
Scenarios like these can be described using Big O notation. In programming, Big O notation can be used as a way of determining bottlenecks in code by finding the worst case scenario - the most amount of iterations potentially required that is. The scenario above with N * M iteration would be described as O(N * M) - or given that N and M are almost equal, we could stretch it to O(N^2). This is an exponential curve, which should be avoided as far as possible.
Luckily there are other types of collections we can use instead. For instance a dictionary, which is build up of key and value pairs. If we already know the key (eg. the external ID of the product), a lookup will only take a single iteration (described as O(1) using the Big O notation) regardless of the size of the dictionary. We still have to iterate through all the products in productList.Products (which was O(N)), and we'll also have to create the dictionary based on children, which then will be O(M). In the end, these put together can be described as O(M + N + M). This is a linear curve, which is much better. With 1000 products, the worst case scenario is now 3000 iterations - which is a lot less than the 1000000 iterations we had before.
I've tried to illustrate the difference between O(N * M) and O(N + M) with the two diagrams below:
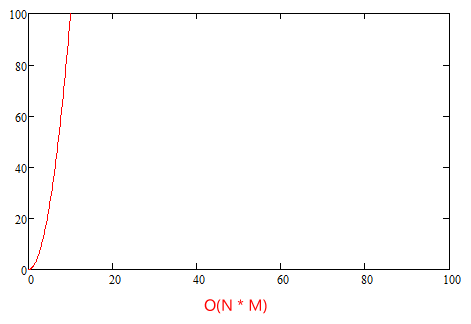
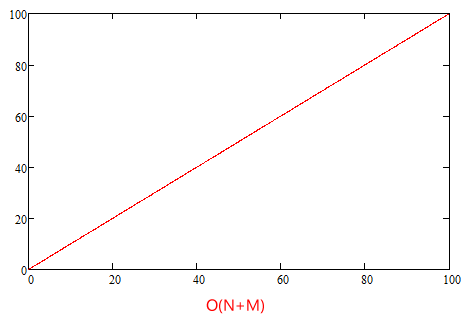
The code still has other loops and iterations as well - eg. parsing the products in the JSON file or getting the children of the container node. But these are linear as well, so even though it still affects performance slightly, we are no way near the 1000000 iterations for 1000 products.
Changing the code to use a dictionary instead could something look like:
// Make the full path of the JSON file
string path = IOHelper.MapPath("~/App_Data/Products.json");
// Read the raw contents of the file
string contents = System.IO.File.ReadAllText(path);
// Deserialize the products
ProductList list = JsonConvert.DeserializeObject<ProductList>(contents);
// Get a reference the container node
IPublishedContent container = Umbraco.TypedContent(1234);
// Get all children (products) from the container
Dictionary<string, IPublishedContent> children = container.Children.ToDictionary(x => x.GetPropertyValue<string>("productId");
// Iterate through each product from the JSON file
foreach (Product product in list.Products) {
// Has the product already been imported?
IPublishedContent content;
if (children.TryGetValue(product.Id, out content)) {
// update product
} else {
// add product
}
}The code should now perform a lot better 😄
Should we use the content cache?
In my examples so far, I've been using the content cache for finding existing products. The content cache is really fast, but is it really reliable for the sort of thing we're doing? Perhaps not.
We could have a scenario where editors would unpublish a product, or there would be some sort of scheduling determining when the product should be published and unpublished. As the content cache only exposes published content, we can't use it for checking whether a product already exists in Umbraco.
Examine could be another choice, as it's similar fast, and Umbraco has an internal index for content, which also includes unpublished content. But in our experience, Examine isn't reliable either for this kind of task. The index could be corrupt, or simply not available when we need it (eg. if it's being rebuild). Wrongly determining that a product hasn't yet been imported, could lead to the same product being added twice.
In addition to what's described above, we also need get a reference to the IContent's representing the products in Umbraco, as we need it when we use the content service to update the product. So we could just use the content service for creating the dictionary as well.
The content service hits the database, so it's slower that the content cache and Examine, but it should be the most reliable, and the extra time shouldn't really matter as we'd ideally be running the import in a background task.
By replacing the content cache with the content service, the code should then look something like:
// Make the full path of the JSON file
string path = IOHelper.MapPath("~/App_Data/Products.json");
// Read the raw contents of the file
string contents = System.IO.File.ReadAllText(path);
// Parse the raw JSON into a list of products
ProductList list = JsonConvert.Deserialize<ProductList>(contents);
// Get all children (products) from the container
Dictionary<string, IPublishedContent> children = ContentService.GetChildren(1234).ToDictionary(x => x.GetValue<string>("externalId");
// Iterate through each product from the JSON file
foreach (Product product in list.Products) {
// Has the product already been imported?
IContent content;
if (children.TryGetValue(product.Id, out content)) {
// update product
} else {
// add product
}
}Minimizing the data saved in the local database
With the import logic we have right now, we'll just either add or update a product. Given that the goal is to run an automated import of products, it might be a good idea to have a look at how much data we're saving to the database - and whether we can to anything to minimize that.
For this, there is a few things we should consider:
Should we always either add or update a product?
The simple answer: No. There may not always be changes for a given product, so we should have some way of checking whether a product has been changed at the source.
When you save a content item in Umbraco, the new version is added to the database, but old versions are still kept in the database - eg. so editors can use the rollback feature to roll back to an older version. Adding a mechanism to our import logic that makes sure we only update the content item when we have to, will help keeping the amount of content versions to a minimum.
As an example why this matters, we had a solution that would update products every 15 minutes. After doing this for a month or so, the backoffice had become pretty slow from all the content versions that had been added to the database over this period. In our defense, it was a site still under development, but still pretty bad 😂
Adding logic to determine whether we actually need to update a product can be done by comparing the new and old values - for JSON, this would be something like:
// Has the product already been imported?
IContent content;
if (children.TryGetValue(product.Id, out content)) {
// Get the old and new data values
string oldValue = content.GetValue<string>("productData");
// Serialize the product to a raw JSON string
string newValue = JsonConvert.SerializeObject(product);
// Does the two values match?
if (oldValue == newValue) continue;
// update product
} else {
// add product
}In theory this should be fairly simple, but there is a few things you should be aware of when saving JSON in Umbraco:
-
The default behavior of the JsonConvert.Serialize method is not to apply any formatting to the generated JSON - meaning that the JSON isn't indented. This is actually what we want, as indented JSON takes up more space. But if a user later saves the product via the backoffice in Umbraco, the JSON will now be saved as intended. I've raised an issue for this, as I think what Umbraco is doing is wrong: Umbraco shouldn't store JSON property data as indented
A way to get around of this could be to make sure the JSON we're saving via the content service is also indented - eg. JsonConvert.Serialize(product, Formatting.Indented). But then this would take up more space in the database than what is necessary.
-
Like most of the .NET world, Umbraco uses JSON.net to serialize and deserialize JSON. A problem with the default settings of JSON.net is however that it will automatically look for strings that look like dates, and internally keep them as an instances of System.DateTime instead of System.String. The problem here is that the original date format and culture isn't also stored, so when the JSON is later serialized, the date format may be totally different. And the date may be formatted using a culture so the string value later can't be parsed back to an instance of System.DateTime using an invariant culture. I've also raised an issue for this: Default JSON.net configuration corrupts date strings when deserializing JSON data for the backoffice
I haven't really found a good way around this, so my solution so far has been to prefix the serialized JSON string with an underscore - this means that Umbraco will just see the stored value as a regular string, and not try to deserialize the value to a JSON object. Bit of a hack, but it does the job - and also solves the issue with indentation.
To take these issues into account, the code could then be updated to as shown below (I've only updated the line where the new value is being generated):
// Has the product already been imported?
IContent content;
if (children.TryGetValue(product.Id, out content)) {
// Get the old and new data values
string oldValue = content.GetValue<string>("productData");
// Serialize the product to a raw JSON string
string newValue = "_" + JsonConvert.SerializeObject(product);
// Does the two values match?
if (oldValue == newValue) continue;
// update product
} else {
// add product
}Limiting the amount of content versions saved in the database
As mentioned earlier, each time you save a content item in Umbraco, a new version is created, but older versions are still kept in the database. Storing previous versions can take up a lot of extra space in the database, and eventually also start to affect the performance of the backoffice.
The step with the comparison explained above only prevents adding unnecessary content versions to the database, but if the data changes often, we can still end up with many content versions.
As we're importing the products from an external source, it may not be necessary to store more than a few versions back in time. Luckily Matt Brailsford has created a package called UnVersion, which automatically deletes older versions when a new version is added.
UnVersion can be configured to apply to all content types or for specific content types. For instance, the configuration to keep a maximum of five content versions across all content types look like:
<?xml version="1.0"?>
<unVersionConfig>
<add maxCount="5" />
</unVersionConfig>If we only wish to apply this for products, but not everything else, the configuration could instead look something like:
<?xml version="1.0"?>
<unVersionConfig>
<add docTypeAlias="product" maxDays="14" maxCount="5" />
</unVersionConfig>In this example, I've specified both the maxDays and maxCount attributes. When both attributes are specified, content versions not matching both attributes will be deleted.
Populating the properties in Umbraco
So far I've omitted the part that actually adds or updates the products in Umbraco as well as populates the properties with the right data. For this scenario, we're also using the content service.
Adding a new product
In this demo, the idea is that when we're adding a product, we should save all the JSON data from the source in a single property, but also update other properties with relevant information. Eg. the product name and description, which then later can be edited by an editor.
The first step here is to create a new content item (only in memory for now):
// Create a new content item
content = ContentService.CreateContent(product.Name, 1234, "product");For the CreateContent method, the first parameter is the name of the product. The second parameter is the ID of the container node under which we wish to add the product. The third parameter is the alias of the content type - in this case product.
Next, we'll need to update the individual properties. Most properties are either string or integer values, but the properties for the product features and product photos are a bit more complex, as they are using Nested Content and the media picker respectively.
For the product features, we can mimic the JSON data stored by Nested Content. The generation of this JSON value is handled by the GetFeaturesValue method. In a similar way, the photos are handled by the ImportImages method, which will both import the images if necessary as well as generate the correct media picker value with the UDIs of the photos. The implementation of both methods can be found at the bottom of the ProductsService.cs file.
As we now have the correct values to save in Umbraco, the logic for updating the properties looks something like:
// Import the product image(s)
string images = ImportImages(existingImages, product);
// Set the properties
content.SetValue("productName", product.Name);
content.SetValue("price", product.Price);
content.SetValue("category", String.Join(",", product.Categories));
content.SetValue("description", product.Description);
content.SetValue("sku", product.Sku);
content.SetValue("photos", images);
content.SetValue("features", GetFeaturesValue(product));
content.SetValue("productId", product.Id);
content.SetValue("productData", "_" + JsonConvert.SerializeObject(product));With the properties populated, we can go ahead and publish the product:
// Save and publish the product
ContentService.SaveAndPublishWithStatus(content, ProductConstants.ImportUserId);You might instead just save the product, and then let an editor manually publish the product - if that is the case, the code should instead be:
// Save and publish the product
ContentService.Save(content, ProductConstants.ImportUserId);Updating an existing product
Updating is a bit different from adding a product, as we already have populated the various properties. And an editor may have changed the different values - eg. if the name of the product that should be displayed on the website differs from the product name from the external source. This is of course an individual thing from solution to solution, but we should then probably only update certain properties, and thus the code could look as:
// Update all readonly properties
content.SetValue("price", product.Price);
content.SetValue("productData", "_" + JsonConvert.SerializeObject(product));For our fictional shop, the price is controlled at the external source, so we should update it in Umbraco if it has changed. The JSON data stored in the productData could also have information we haven't added to the other properties, so we should update that as well.
With the properties updated, we can now go ahead and save and publish the changes:
// Save and publish the product
ContentService.SaveAndPublishWithStatus(content);Again, you could use the Save method instead if changes are not supposed to be published automatically. Or add a check so we use the SaveAndPublish method if the content item already is published, but the Save method if it isn't.
Deleting existing products?
As a product might be deleted at the source, this change should most likely also be reflected in the import logic. As we initially created a dictionary of all existing products in Umbraco, we can delete products from that dictionary as we either add or update them in Umbraco. Eg something like:
// Remove the product from the dictionary
existing.Remove(product.Id);
When we're done iterating over the products from the source, we can then delete the remaining products from Umbraco:
// Any products left in "existing" no longer exists in the JSON file and should be deleted
foreach (IContent content in existing.Values) {
// Delete the product in Umbraco
ContentService.Delete(content);
}Nice to have
While I won't go much into detail about it here, the ProductsService class has a bit extra logic that might be useful.
For instance, when we change content using the content service, those changes will by default be attributed to the user with ID 0. This isn't always ideal, so you can create a backoffice user only to be used for the products import. The ID of this user can then be specified as an optional parameter for the CreateContent and SaveAndPublishWithStatus methods. Having attributed actions triggered by the import job, the history of a product will then look like:
To keep track of how the import goes, the ImportProducts method is also building a list with the status of each product, whether it was Added, NotModified, Updated or Deleted.
Setting up a scheduled task for importing the products at a certain interval
Umbraco natively comes with a way of setting up scheduled task, which then can execute our import logic with a certain interval. A scheduled task in Umbraco points to a URL, which is then accessed when the scheduled task is triggered.
Umbraco's scheduled tasks are controlled by the ~/config/umbracoSettings.config file and specifically the scheduledTasks element:
<scheduledTasks>
<!-- add tasks that should be called with an interval (seconds) -->
<!-- <task log="true" alias="test60" interval="60" url="http://localhost/umbraco/test.aspx"/>-->
</scheduledTasks>If you for instance have an API controller for triggering an import, you could add the a scheduled task like shown below:
<scheduledTasks>
<!-- add tasks that should be called with an interval (seconds) -->
<!-- <task log="true" alias="test60" interval="60" url="http://localhost/umbraco/test.aspx"/>-->
<task alias="ProductsImport" interval="900" url="http://myshop.com/umbraco/api/Products/Import"/>
</scheduledTasks>The interval is specified in seconds, so 900 seconds is the same as 15 minutes.
Alternatives?
The implementation for scheduled tasks in Umbraco is however a bit old, and don't really offer more options that the one shown above. So there may be better alternatives.
There are external tools that provide somewhat similar service. We have sometimes used Azure's Scheduler Job Collections, which provides a few more options than those of Umbraco's scheduled tasks. If you're using another hosting provider, they might have something similar.
And the winner is...
For some time now, we've been using Hangfire. Per their own description, it's a tool that gives you an:
Incredibly easy way to perform fire-and-forget, delayed and recurring jobs inside ASP.NET applications. CPU and I/O intensive, long-running and short-running jobs are supported. No Windows Service / Task Scheduler required. Backed by Redis, SQL Server, SQL Azure and MSMQ.
A recurring job in Hangfire triggers a method in your own C# code, so you'll have access to the various services of Umbraco. But keep in mind that as the recurring jobs are running in a background thread, you won't have access to UmbracoContext.Current and HttpContext.Current.
Hangfire is also quite easy to setup. If you install their NuGet package, you'll only need to setup an OWIN (Open Web Interface for .NET) startup file. You can see an example on how to setup Hangfire from my OWIN startup file in the demo repository.
Hangfire also provides a dashboard with an overview of the various jobs you might have in your solution. It is however mostly limited to showing whether jobs have failed or succeeded, but not what's going on inside a particular job.
Luckily there is a great third party package called Hangfire.Console which adds console-like support to Hangfire. This means that Hangfire can give us a result looking something like shown in the image below:
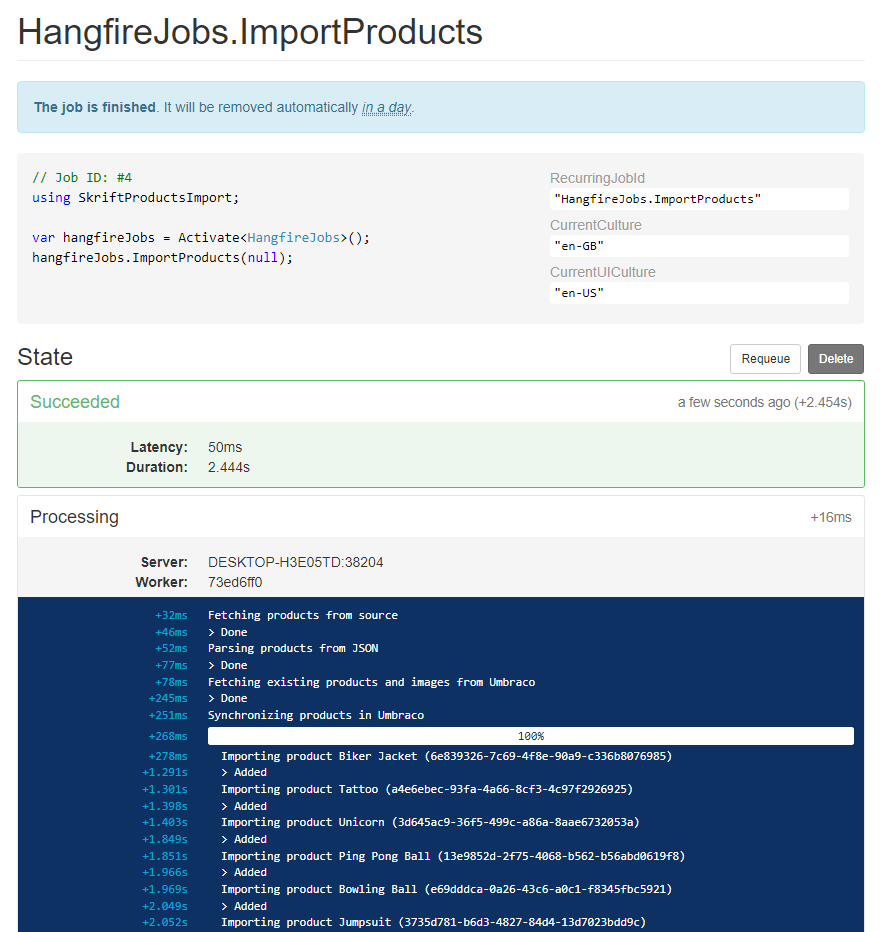
You should however be aware that my Hangfire configuration is outcommented by default, as SQL CE (as the demo solution is using) is not supported by Hangfire. You'll need a full SQL or SQL express database to use Hangfire.
Besides installing the two packages, you can see the steps to configure Hangfire from this commit.
Wrapping things up and getting to play around
The demo solution is based on The Starter Kit, and it therefore reuses the existing content type for a product. I have deleted all existing products (as well as their images). I've then created a dashboard in the content section that lets editors manually trigger a new import. Once the import finishes, a table with the status for each product will be shown.
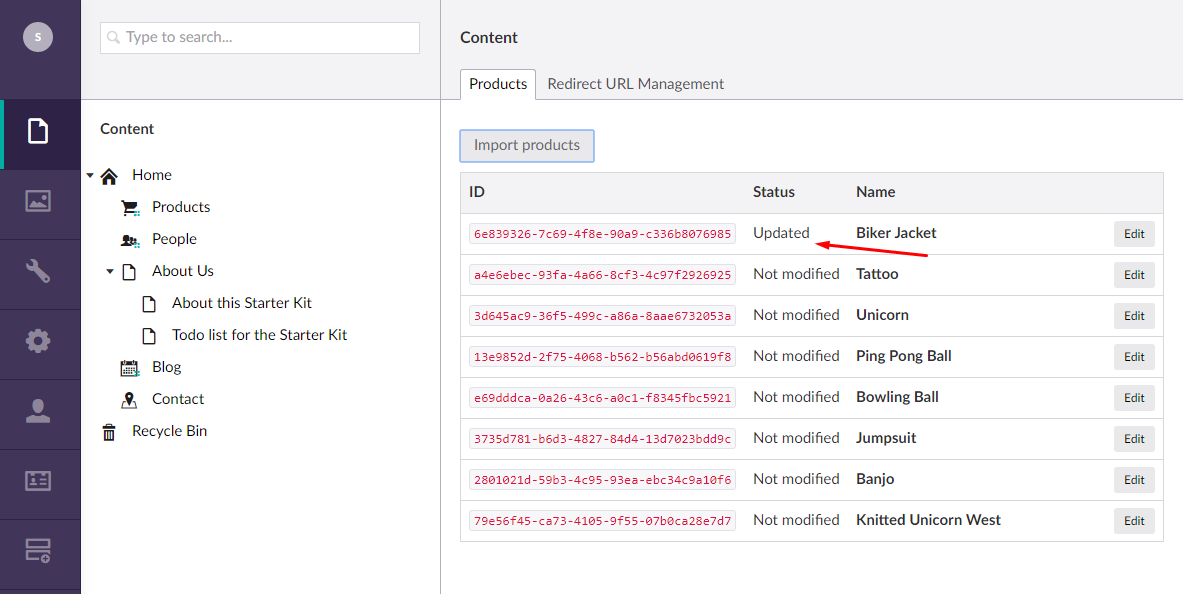
Obviously if the shop has many products, the table might need some pagination. Or products not modified could just be hidden from the list.
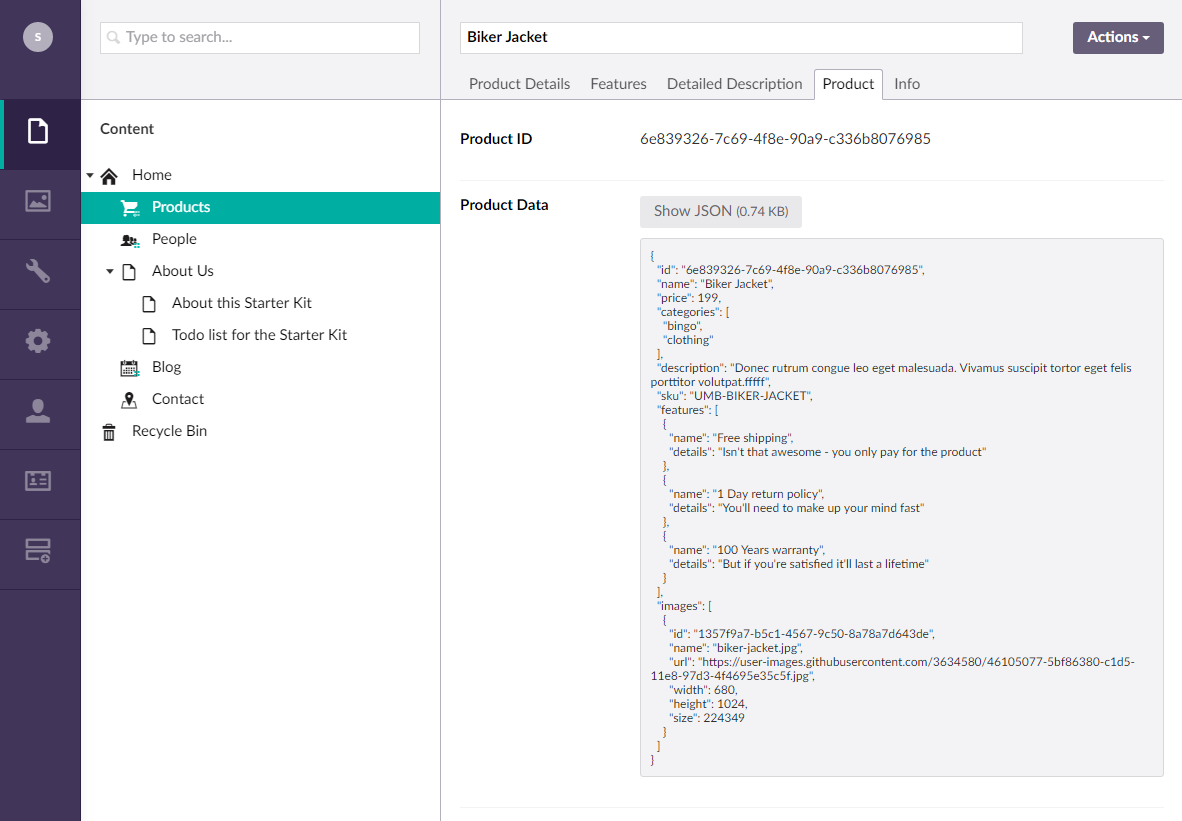
As shown in the earlier examples, the JSON value for the product data is saved to it's own property. Normally I'm then creating a simple property editor with a Show JSON-button so the raw JSON is nicely tucked away, but still accessible if you need to have a look at it. You can also find the implementation for this in the repository.
The JSON data could have other information which we haven't populated to the individual properties, but still use on the actual website. So if the editors of your shop also need to look at this data, you could go a bit longer and visualize the data. It could just be something as simple as this:
If you have a look at the ProductsService.cs, you might notice that it differs a bit from the examples in this article. For instance, the ImportProducts method takes an instance of PerformContext as it's only parameter (which is optional, and thereby null if you don't specify any parameters when calling the method).
The PerformContext class comes from Hangfire, and in combination with Hangfire.Console, it's used for logging what's going on inside the Hangfire job. The WriteLine, WriteProgressBar, and WithProgress methods you'll see in my implementation are all extension methods from Hangfire.Console. They are totally fine to use even if the reference to the PerformContext is null.