
Indexing, searching and extending Lucene in Umbraco 8
Onsite or internal search is often a poor relation to other sexier features of a site such as the primary navigation or rich integrations with external systems such as CRM. On average 30% of users will do an onsite search, and doing so is a strong predictor of likelihood to convert (see Moz).
Onsite search is challenging though, internal search engines can never rival Google for quality and accuracy of results - because they can't rely on the many ranking factors that Google uses.
However, the Lucene search engine which forms part of the core of Umbraco does provide a rich search API which is super fast, coupled with the fact that much of the indexing scaffolding is already built into the core means that a fast and feature rich onsite search can be achieved in Umbraco 8 within a few hours of development.
Umbraco’s built-in search engine API Examine uses Lucene.Net to provide fast free text search of content in the CMS. How developers configure and use these API has changed substantially in Umbraco 8, and in this article we’ll look at how to build a simple free text search, which can cope with hidden, protected and multilingual content as well as content from 3rd party, external sources.
Introduction
Search has come a long way in Umbraco since I started using Umbraco back in 2008. Way back then we were writing sites using XSLT templates and WebForms if we were smart, and XSLTSearch by Doug Robar was the go to search engine for Umbraco sites built using Umbraco 3 and 4.
But in 2009 Shannon Deminick started working on a new search API which wraps the popular Lucene.Net search engine (itself a port of Lucene), this was then incorporated into the core of Umbraco in 2010. Lucene.Net is an extremely fast search engine that provides full-text search, multi-index searching, and fuzzy searching.
Examine and Lucene are often used in Umbraco sites to provide free-text onsite search on the front end of websites, and is also built into the backend of Umbraco to enable Editors to easily find and edit content. But beyond these simple use-cases Lucene can be used to provide related content searches (think the “people who bought this also bought these items” features on Amazon) and can also provide very fast access to content in code, rather than traversing content via the Umbraco IPublishedContent API or ModelsBuilder.
Because Examine is in the core of Umbraco a lot of the scaffolding that would be needed to get up and running has been done for you, with built in indexes of Published Content used for external search, as well as indexes of unpublished content, Members and Users. This speeds up the effort needed to index and search Umbraco Content, and Examine can be extended to also index and search external content.
While Examine provides a fluent API which wraps the Lucene query language, in earlier versions of Umbraco, getting up and running with Examine has been much simplified still by the package EZSearch, which provided a Partial View Macro which could be dropped into a site to provide simplified drag and drop, configurable free text search of Umbraco content.
In Umbraco 8 much of the APIs for Examine have substantially changed, like lots of other APIs in the core of the CMS, and sadly there’s no plans currently to upgrade EZSearch so it can be challenging to get site search up and running if your MVC coding skills aren't strong. However, all the functionality remains, and we’ll cover the key changes needed to implement a basic free text search, respecting hidden and protected content, as well as multilingual content and content stored in third-party systems.
Basic searching and indexing in Umbraco
By default Umbraco has built in indexes of published content, unpublished changes, Members and Users. In normal use, a public facing website search engine will use the External index.
In the example below, SearchResultsPageController is responsible for building the view model by calling querySearchIndex() which creates an Examine Searcher using TryGetSearcher(Constants.UmbracoIndexes.ExternalIndex, out ISearcher searcher), constructs a query where I chose to do a GroupedOr() type of search.
Finally we call GetPagedSearchResults which jumps to the current page of search results and picks the next 10 items mapping them into a SearchResultViewModel.
SearchResultsPageController.cs
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Linq;
using System.Text.RegularExpressions;
using System.Web.Mvc;
using Umbraco.Web.Mvc;
using Examine;
using Examine.Search;
using C6Ddemo.Core.ViewModels;
using Umbraco.Web.Models;
namespace C6Ddemo.Core.Controllers.RenderMvcControllers
{
public class SearchResultsPageController : RenderMvcController
{
public override ActionResult Index(ContentModel model)
{
SearchViewModel viewModel;
string searchTerm = ("" + Request["q"]).ToLower(CultureInfo.InvariantCulture);
if (searchTerm.Length > 0)
{
int currentPage = int.TryParse(Request["p"], out int parsedInt) ? parsedInt : 1;
int pageSize =10;
ISearchResults searchResults = querySearchIndex(searchTerm);
viewModel = new SearchViewModel(model.Content)
{
ResultsCount = searchResults.TotalItemCount,
PagedResults = GetPagedSearchResults(searchResults, pageSize, currentPage),
TotalPages = (int)Math.Ceiling((decimal)searchResults.TotalItemCount / pageSize),
PageSize = pageSize,
SearchTerm = searchTerm,
CurrentPage = Math.Max(1, Math.Min((int)Math.Ceiling((decimal)searchResults.TotalItemCount / pageSize), currentPage))
};
}
else
{
viewModel = new SearchViewModel(model.Content)
{
ResultsCount = 0,
TotalPages = 0,
PageSize = 0,
SearchTerm = "",
CurrentPage = 0
};
}
return CurrentTemplate(viewModel);
}
private ISearchResults querySearchIndex(string searchTerm)
{
if (!ExamineManager.Instance.TryGetIndex(Constants.UmbracoIndexes.ExternalIndex, out var index))
{
throw new InvalidOperationException($"No index found with name {Constants.UmbracoIndexes.ExternalIndex}");
}
ISearcher searcher = index.GetSearcher();
IQuery query = searcher.CreateQuery(null, BooleanOperation.And);
string searchFields="nodeName,pageTitle,metaDescription,bodyText";
IBooleanOperation terms = query.GroupedOr(searchFields.Split(','), searchTerm);
return terms.Execute();
}
private IEnumerable GetPagedSearchResults(ISearchResults searchResults, int pageSize, int currentPage)
{
var viewModels = new List();
foreach (var result in searchResults.Skip(pageSize * (currentPage - 1)).Take(pageSize))
{
SearchResultViewModel viewModel;
var node = Umbraco.Content(result.Values["id"]);
viewModel = new SearchResultViewModel()
{
Url = node.Url,
Title = result.Values["pageTitle"],
Description = result.Values["metaDescription"]
};
viewModels.Add(viewModel);
}
return viewModels;
}
}
}
SearchResultsPage.cshtml is a view which iterates over the PagedResults, and then outputs back and next buttons.
SearchResultsPage.cshtml
@using C6Ddemo.Core.ViewModels
@using ContentModels = C6Ddemo.Core.Models
@inherits Umbraco.Web.Mvc.UmbracoViewPage<SearchViewModel>
@{
Layout = "internalMaster.cshtml";
}
<section id="searchbox">
<div id="queryboxy">
<form method="get" action="/search-results">
<label for="searchterm">Search:</label> <input id="searchterm" name="q" type="search" value="@Model.SearchTerm" />
<button type="submit">Search</button>
</form>
</div>
</section>
@if (Model.SearchTerm != "")
{
<section id="searchresults">
@if (Model.ResultsCount > 0)
{
<div class="currentPageSearchMetadata">
<p>Page @Model.CurrentPage of @Model.ResultsCount results.</p>
</div>
<ul>
@foreach (var result in Model.PagedResults)
{
<li>
<span class="url">
<a href="@result.Url">@result.Title</a>
</span>
<span class="snippetDescription">
@result.Description
</span>
</li>
}
</ul>
if (Model.TotalPages > 1)
{
<div class="pagecontrols">
@{
string baseSearchUrl = String.Format("?q={0}", Model.SearchTerm);
if (Model.CurrentPage > 1)
{
string backSearchUrl = String.Format(baseSearchUrl + "&p={0}", Model.CurrentPage - 1);
<a href="@backSearchUrl" class="searchNavBack">Back</a>
}
if (Model.CurrentPage < Model.TotalPages-1)
{
string nextSearchUrl = String.Format(baseSearchUrl + "&p={0}", Model.CurrentPage + 1);
<a href="@nextSearchUrl" class="searchNavNext">Next</a>
}
}
</div>
}
}
else
{
<p>No results found.</p>
}
</section>
}
I find constructing Lucene searches to be quite challenging, for some reason, the semantics of the search syntax seems counter intuitive. In the example above I used an Examine GroupedOr condition, where there are multiple fields listed and multiple terms which will perform a broad search for Umbraco content (see more detail in the Examine Documentation). Tweaking the list of fields searched and the operations used is where the magic happens enabling you to provide users with a slick search interface.
It’s common to exclude pages with certain fields set such as umbracoNaviHide, which can be achieved by adding an additional term that excludes pages with values of “1”. Because there are a number of page values I usually want to suppress from the results I create a web.config setting to store all these fields, but show a constant for umbracoNaviHide here for simplicity:
string pageExclusionFields = "umbracoNaviHide";
terms = terms.Not().GroupedOr(pageExclusionFields.Split(','), 1.ToString());
If the site contains Protected content behind a login gate, then it’s often sensible to filter out pages that are Protected which the current user doesn’t have permission to view.
Searching multilingual content
In previous versions of Umbraco it was possible to search multilingual sites by constraining the search to focus on the descendents of a given language variant’s home node. However, in Umbraco 8 with the introduction of true multilingual variants into Umbraco, searching multilingual content has become more complex, as all variants of all fields on a Node are stored in Lucene in the same record.
To filter only on fields of a given language you should search on fields with _{culture_code} in the Lucene Index. For example, to search the pageTitle in British English search for pageTitle_en_gb. To generalise for this, I created a string of all possible fields I wish to search on, and string replace the Culture Code:
string currentCulture = System.Threading.Thread.CurrentThread.CurrentCulture.Name.ToLower();
string searchFields = "nodeName,pageTitle_{0},metaDescription_{0}"
terms = query.GroupedOr(String.Format(SearchFields, currentCulture).Split(','), searchTerm);
Indexing and searching PDF content
Out of the box, the External Searcher includes Media Items, so it's possible to search for terms found in Media Item names. However, it can be useful to index the content of PDFs which is only a relatively minor extension of the third party content.
To index PDF content install the package UmbracoExamine.PDF, once installed and the site started up you'll get a new index called PDFIndex which indexes the content of the PDF to a field called fileTextContent. Searching the contents of that Index requires the creation of a Searcher and a query.
Searching PDF content - SearchResultsPageController.cs
private ISearchResults querySearchIndex(string searchTerm)
{
if (!ExamineManager.Instance.TryGetIndex("PDFIndex", out var index))
{
throw new InvalidOperationException($"No Index found with name PDFIndex");
}
ISearcher searcher = index.GetSearcher();
IQuery query = searcher.CreateQuery(null, BooleanOperation.And);
string searchFields="fileTextContent";
IBooleanOperation terms = query.GroupedOr(searchFields.Split(','), searchTerm);
return terms.Execute();
}
If you want to create a single master search page that includes Content, Media and PDFs, then you'll need to create a multi-index Searcher that spans the External Index and your PDF index.
It is possible to create a Multi Index Searcher each time you want to run a query, however, creating the index and registering it at start-up makes it possible for the Searcher to be viewed and queried in the backend Examine manager.
To create the Searcher at start-up, you must use dependency injection composers and components. At startup Umbraco determines which components should be used to deliver the expected behaviour of your site, this can be customised by developing Composers and Components. The composer determines the dependencies, and the Component implements your custom code.
In this composer we have a dependency that it must run after ExaminePDF and the component creates the Searcher and registers it.
Creating a Multi Index Searcher - SearchComposer.cs
[ComposeAfter(typeof(ExaminePdfComposer))]
public class RegisterPDFMultiSearcherComposer : ComponentComposer<RegisterPDFMultiSearcherComponent>, IUserComposer
{
}
public class RegisterPDFMultiSearcherComponent : IComponent
{
private readonly IExamineManager _examineManager;
public RegisterPDFMultiSearcherComponent(IExamineManager examineManager)
{
_examineManager = examineManager;
}
public void Initialize()
{
if (_examineManager.TryGetIndex(Constants.UmbracoIndexes.ExternalIndexName, out var externalIndex)
&& _examineManager.TryGetIndex("PDFIndex", out var pdfIndex))
{
var multiSearcher = new MultiIndexSearcher("PDFMultiSearcher", new IIndex[] { externalIndex, pdfIndex });
_examineManager.AddSearcher(multiSearcher);
}
}
public void Terminate() { }
}
Once registered, you can use TryGetSearcher in code to perform a query.
Remember that it's possible for the same PDF to appear twice in your results if they are matched both in the External Index because of their node name, and in your PDF index, so you'll need to suppress one of them from the results. I chose to ignore all media items in the External Index, by filtering out those records with __IndexType:"media".
SearchResultsPageController.cs
private ISearchResults querySearchIndex(string searchTerm)
{
if (!ExamineManager.Instance.TryGetSearcher("PDFMultiSearcher", out ISearcher searcher))
{
throw new InvalidOperationException($"No Searcher found with name PDFMultiSearcher");
}
IQuery query = searcher.CreateQuery(null, BooleanOperation.And);
string searchFields="fileTextContent,pageTitle,metaDescription,bodyText";
IBooleanOperation terms = query.GroupedOr(searchFields.Split(','), searchTerm);
string pageExclusionFields = "umbracoNaviHide";
terms = terms.Not().GroupedOr(pageExclusionFields.Split(','), 1.ToString());
terms = terms.Not().Field("__IndexType", "media");
return terms.Execute();
}
Indexing and searching external content
In a recent project, my client had a requirement to search and index third-party content alongside Umbraco content, specifically support articles held in Zendesk. In order to achieve this, you first need to index this third-party content. Once the content has been retrieved via an API and added to the index, it’s then possible to search the content.
Indexing third-party content
First things first we need to pull in and index the third-party content. In Umbraco this is achieved using an Indexer, which must be loaded at project start up using a Composition.
ZendeskArticleIndexCreator is responsible for creating the LuceneIndex, including the definition of each of the Fields we intend to index on. The field definitions created will depend entirely on the data available on the Third Party service you integrate with, mine are quite specific to Zendesk articles.
ZendeskArticleIndexCreator.cs
using System.Collections.Generic;
using Umbraco.Core.Logging;
using Umbraco.Core.Services;
using Examine;
using Lucene.Net.Util;
using Umbraco.Examine;
using Umbraco.Web.Search;
using Lucene.Net.Analysis.Standard;
using Examine.LuceneEngine.Providers;
namespace C6Ddemo.ZendeskExamineIndexer.Examine
{
public class ZendeskArticleIndexCreator : LuceneIndexCreator
{
public override IEnumerable<IIndex> Create()
{
var index = new LuceneIndex("ZendeskArticleIndex",
CreateFileSystemLuceneDirectory("ZendeskArticleIndex"),
new FieldDefinitionCollection(
new FieldDefinition("Body", FieldDefinitionTypes.FullTextSortable),
new FieldDefinition("Title", FieldDefinitionTypes.FullText),
new FieldDefinition("Id", FieldDefinitionTypes.Long),
new FieldDefinition("Html_url", FieldDefinitionTypes.FullText),
new FieldDefinition("DocumentType", FieldDefinitionTypes.FullText)
),
new StandardAnalyzer(Version.LUCENE_30));
return new[] { index };
}
}
}
ZendeskArticleValueSetBuilder is responsible for mapping from our Article model’s to an ExamineValueSet.
ZendeskArticleValueSetBuilder.cs
using System.Collections.Generic;
using C6Ddemo.ZendeskExamineIndexer.Models;
using Umbraco.Examine;
using Examine;
namespace C6Ddemo.ZendeskExamineIndexer.Examine
{
public class ZendeskArticleValueSetBuilder : IValueSetBuilder<Article>
{
public IEnumerable<ValueSet> GetValueSets(params Article[] articles)
{
foreach (var article in articles)
{
var indexValues = new Dictionary<string, object>
{
["Id"] = article.Id,
["Html_url"] = article.Html_url,
["Title"] = article.Title,
["Body"] = article.Body,
["DocumentType"] = "ZendeskArticle"
};
var valueSet = new ValueSet(article.Url.ToString(), "article", indexValues);
yield return valueSet;
}
}
}
}
ZendeskArticleIndexPopulator populates our custom index with content whenever it needs to be rebuilt.
ZendeskArticleIndexPopulator.cs
using C6Ddemo.ZendeskExamineIndexer.Models;
using Examine;
using System.Collections.Generic;
using System.Linq;
using Umbraco.Examine;
namespace C6Ddemo.ZendeskExamineIndexer.Examine
{
public class ZendeskArticleIndexPopulator : IndexPopulator
{
private readonly ZendeskArticleValueSetBuilder _zendeskArticleValueSetBuilder;
public ZendeskArticleIndexPopulator (ZendeskArticleValueSetBuilder zendeskArticleValueSetBuilder)
{
_zendeskArticleValueSetBuilder = zendeskArticleValueSetBuilder;
RegisterIndex("ZendeskArticleIndex");
}
protected override void PopulateIndexes(IReadOnlyList<IIndex> indexes)
{
ZendeskAPI zendesk = new ZendeskAPI();
List<Article> articles = zendesk.GetHelpdeskArticles();
if (articles != null && articles.Any())
{
foreach (var index in indexes)
{
index.IndexItems(_zendeskArticleValueSetBuilder.GetValueSets(articles.ToArray()));
}
}
}
}
}
You’ll note I call a class ZendeskAPI which is a Poco I created using RestSharp, this could be improved by passing this in via DI. GetHelpdeskArticles() makes a series of GET requests on the Zendesk article API and builds a list of articles.
Finally, the ZendeskArticleComposer is responsible for Composing the DI Component’s required to implement our index.
ZendeskArticleComposer.cs
using Umbraco.Core;
using Umbraco.Core.Composing;
namespace C6Ddemo.ZendeskExamineIndexer.Examine
{
[RuntimeLevel(MinLevel = RuntimeLevel.Run)]
public class ZendeskArticleComposer : IUserComposer
{
public void Compose(Composition composition)
{
composition.Components().Append<ZendeskArticleComponent>();
composition.RegisterUnique<ZendeskArticleValueSetBuilder>();
composition.Register<ZendeskArticleIndexPopulator>(Lifetime.Singleton);
composition.RegisterUnique<ZendeskArticleIndexCreator>();
}
}
public class ZendeskArticleComponent : IComponent
{
private readonly IExamineManager _examineManager;
private readonly ZendeskArticleIndexCreator _articleIndexCreator;
public ZendeskArticleComponent(IExamineManager examineManager, ZendeskArticleIndexCreator articleIndexCreator)
{
_examineManager = examineManager;
_articleIndexCreator = articleIndexCreator;
}
public void Initialize()
{
foreach (var index in _articleIndexCreator.Create())
{
_examineManager.AddIndex(index);
}
}
public void Terminate() { }
}
}
When built and run for the first time, you should find a new Index in the Examine Management section of the Umbraco Backend. If all is working well you should find a number of documents have been indexed, and you can perform simple searches in the backend to retrieve Zendesk indexed content from the new Index.
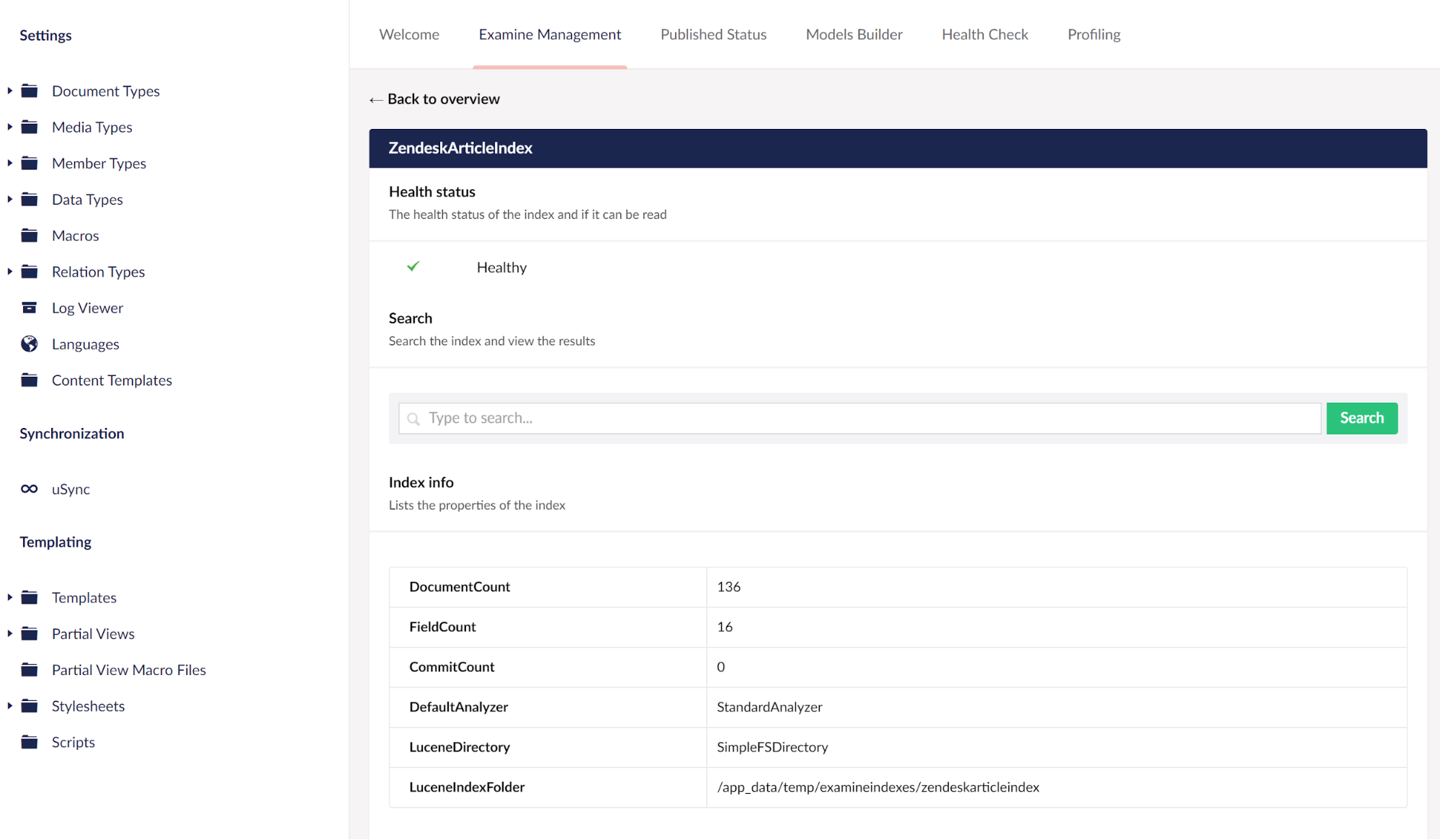
The new Index in the Examine Management section
Searching third-party content
Like with PDFs above, we can choose to search the third party index alone, by creating a Searcher on the new ZendeskArticleIndex Index.
However, if you want to present results of your third-party Index inline with Umbraco content, you’ll again need to create a Multi-index searcher. Below SearchComponent is updated to create a multi index search spanning PDFContent and Zendesk articles.
SearchComposer.cs
using C6Ddemo.Core.Exceptions;
using C6Ddemo.ZendeskExamineIndexer.Examine;
using Examine;
using Examine.LuceneEngine.Providers;
using Lucene.Net.Analysis.Standard;
using Umbraco.Core;
using Umbraco.Core.Composing;
using UmbracoExamine.PDF;
using Umbraco.Core.Logging;
using Version = Lucene.Net.Util.Version;
using Umbraco.Web;
namespace C6Ddemo.Core.Composers
{
[ComposeAfter(typeof(ExaminePdfComposer))]
[ComposeAfter(typeof(ZendeskArticleComposer))]
public class SearchComposer : ComponentComposer<SearchComponent>, IUserComposer
{
}
public class SearchComponent : IComponent
{
private readonly IExamineManager _examineManager;
public SearchComponent(IExamineManager examineManager)
{
_examineManager = examineManager;
}
public void Initialize()
{
String indexsetnames = "ExternalIndex,ZendeskArticleIndex,PDFIndex";
string[] IndexSets = indexsetnames.Split(',');
IIndex[] indexes = new IIndex[IndexSets.Length];
for (int i = 0; i < IndexSets.Length; i++)
{
if (!ExamineManager.Instance.TryGetIndex(IndexSets[i], out IIndex index))
{
throw new InvalidIndexSetException("IndexSet not found " + IndexSets[i]);
}
indexes[i] = index;
}
MultiIndexSearcher searcher = new MultiIndexSearcher("allContentSearcher",
indexes,
new StandardAnalyzer(Version.LUCENE_30));
_examineManager.AddSearcher(searcher);
}
public void Terminate() { }
}
}
Finally SearchResultsPageController is updated to retrieve results from the allContentSearcher defined in SearchComposer, and populate the view model depending on which of the different sources of content we’ve got (e.g. PDFs, Umbraco Content or Zendesk Articles).
SearchResultsPageController.cs
using System;
using System.Collections.Generic;
using System.Globalization;
using System.Linq;
using System.Text.RegularExpressions;
using System.Web.Mvc;
using Umbraco.Web.Mvc;
using Examine;
using Examine.Search;
using C6Ddemo.Core.ViewModels;
using Umbraco.Web.Models;
using C6Ddemo.ZendeskExamineIndexer.Utilities;
namespace C6Ddemo.Core.Controllers.RenderMvcControllers
{
public class SearchResultsPageController : RenderMvcController
{
public override ActionResult Index(ContentModel model)
{
SearchViewModel viewModel;
string searchTerm = ("" + Request["q"]).ToLower(CultureInfo.InvariantCulture);
if (searchTerm.Length > 0)
{
int currentPage = int.TryParse(Request["p"], out int parsedInt) ? parsedInt : 1;
int pageSize = 10;
ISearchResults searchResults = querySearchIndex(searchTerm, System.Threading.Thread.CurrentThread.CurrentCulture.Name.ToLower());
viewModel = new SearchViewModel(model.Content)
{
ResultsCount = searchResults.TotalItemCount,
PagedResults = GetPagedSearchResults(searchResults, pageSize, currentPage),
TotalPages = (int)Math.Ceiling((decimal)searchResults.TotalItemCount / pageSize),
PageSize = pageSize,
SearchTerm = searchTerm,
CurrentPage = Math.Max(1, Math.Min((int)Math.Ceiling((decimal)searchResults.TotalItemCount / pageSize), currentPage)),
ContentTypeFilter = filterContentType
};
}
else
{
viewModel = new SearchViewModel(model.Content)
{
ResultsCount = 0,
TotalPages = 0,
PageSize = 0,
SearchTerm = "",
CurrentPage = 0,
ContentTypeFilter = ""
};
}
return CurrentTemplate(viewModel);
}
private ISearchResults querySearchIndex(string searchTerm, string currentCulture)
{
if (!ExamineManager.Instance.TryGetSearcher("allContentSearcher", out ISearcher searcher))
{
throw new InvalidOper($"Searcher not found allContentSearcher");
}
IQuery query = searcher.CreateQuery(null, BooleanOperation.And);
IBooleanOperation terms = null;
string searchFields = "nodeName,Title,Body,pageTitle_{0},metaDescription_{0},fileTextContent";
terms = query.GroupedOr(String.Format(searchFields, currentCulture).Split(','), searchTerm);
String pageExclusionFields = "umbracoNaviHide";
if (pageExclusionFields != null && pageExclusionFields != "")
{
terms = terms.Not().GroupedOr(pageExclusionFields.Split(','), 1.ToString());
}
terms = terms.Not().Field("__IndexType", "media");
return terms.Execute();
}
private IEnumerable<SearchResultViewModel> GetPagedSearchResults(ISearchResults searchResults, int pageSize, int currentPage)
{
var viewModels = new List<earchResultViewModel>();
foreach (var result in searchResults.Skip(pageSize * (currentPage - 1)).Take(pageSize))
{
SearchResultViewModel viewModel;
switch (result.Values["__IndexType"])
{
case "pdf":
var media = Umbraco.Media(result.Values["id"]);
viewModel = new SearchResultViewModel()
{
Url = media.Url,
Title = result.Values["nodeName"],
Description = "",
ContentType = result.Values["__NodeTypeAlias"]
};
break;
case "article":
string body = StripHtml.StripTagsRegexCompiled(result.Values["Body"]);
body = (body.Length > 250 ? body.Substring(0, 250) + "..." : body);
viewModel = new SearchResultViewModel()
{
Url = result.Values["Html_url"],
Title = result.Values["Title"],
Description = body,
ContentType = result.Values["DocumentType"]
};
break;
case "content":
var node = Umbraco.Content(result.Values["id"]);
string currentCulture = System.Threading.Thread.CurrentThread.CurrentCulture.Name.ToLower();
viewModel = new SearchResultViewModel()
{
Url = node.Url,
Title = result.Values["pageTitle_" + currentCulture],
Description = result.Values["metaDescription_" + currentCulture],
ContentType = result.Values["__NodeTypeAlias"],
LanguageVariant = currentCulture
};
break;
default:
viewModel = new SearchResultViewModel()
{
Url = "",
Title = result.Values["nodeName"],
Description = "This is a media item pulled from the External Index this shouldn't be showing",
ContentType = "Media"
};
break;
}
viewModels.Add(viewModel);
}
return viewModels;
}
}
}
Wrap Up
Good onsite search is an important feature of many websites. Users that do an onsite search are more than twice as likely to convert compared to those that don't (see Moz). They're a critical part of your site's audience, and they deserve a rich search experience. With Umbraco and Examine, much of the work needed for a comprehensive onsite search is available out of the box, but some requires a relatively small amount of work to set up, and hopefully we've covered enough depth for you to get started with rich search covering Umbraco multilingual content, media, PDFs and external third-party content.
A lot of the examples in this article are based on a mashup of docs and examples on Our and in the Examine docs written by Shannon and Morten.
Thanks also to my colleague Karl who's work on indexing Tweets in the #h5yr project was the basis for me to index third party content. Finally thanks to Alex and Gareth for reviewing and giving feedback.