
"Saving the world?" I hear you ask, with a slight lilt of incredulity in your voice. "Seems unlikely."
Usually, I would agree with you. Web development is rarely life and death, and on the odd occasion you do have the opportunity to make a genuine difference to people's lives there are often so many hoops to jump through and red tape that it can feel insurmountable. However, we also have a unique platform that is wide-reaching, with a vast audience and a utility of skills that have the potential to build things as yet unimagined. This is one of those occasions where there appears to be a niche and a general lack of understanding that could be filled with helpful data and, if there's one true love for me, it's a well-ordered dataset.
So, let's look at how a well-ordered dataset could save the world.
I actually started the work for this article in earnest around the time that Greta Thunberg set off for her boat trip to the UN. As she was tweeting updates from her voyage across the Atlantic, I was following along with my own small voyage into the world of climate change, and it is this voyage that will chart the course of the rest of this article.
For me, it started with a question: what is my impact on climate change? The question seems simple, but the answer is complex, nuanced and non-specific. There seems to be no central data repository that can be used to exactly quantify the things I buy, how I travel or the activities I do. Searching for these answers has brought me here: to the beginnings of an API to make this information available.
What are we building?
We will be looking at using Umbraco (v7) and GraphQL together to map and resolve custom PetaPoco data from a bespoke dashboard and surfacing it as part of the exposed GraphQL API. The base package we will be working with is the community package collaboration between Rasmus J Pedersen and the folks at Offroadcode - you can fork and explore the repository on Github. There is a branch available for the work in this demo also available on GitHub
For those unfamiliar, GraphQL is a tool originally developed by Facebook for graphing trees of data and allowing that data to be accessible through an API. For those familiar with REST APIs, it is similar in some respects - however one of the key differences is that instead of defining arguments and structure on the server-side, the structure of the query is built in the client-side. Thus the parameters that are included in the client-side query are the ones that are returned from the server. For the right usecase it can be a powerful solution that can offer a cohesive and effective solution to all members of a development team. With great power, comes great responsibility, and in this article we are using this power for good.
You can learn more about GraphQL .NET here.
Extending Umbraco: Carbon Footprinting
The first part of the demo involved a custom data section. In the backoffice, we have something that looks a little like this:
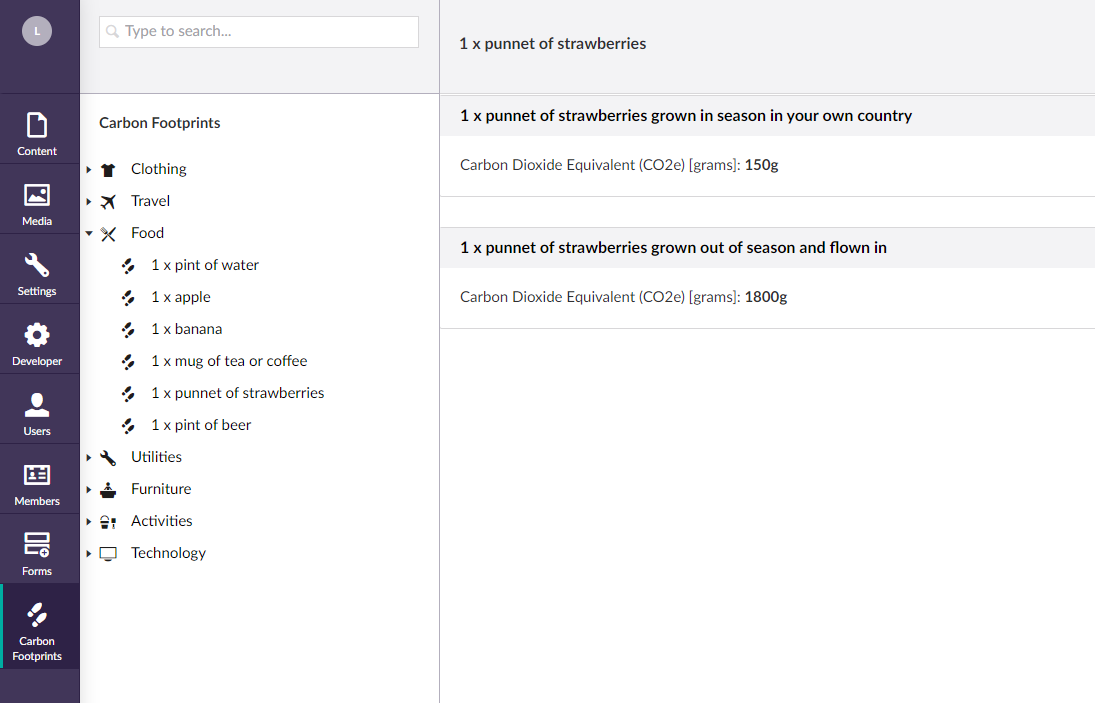
If you would like to learn more about building custom sections for Umbraco v7 there is an excellent Skrift article by Anders Bjerner that will set you in the right direction. You can also poke around the aforementioned branch for this demo, and you'll be able to see how the code is pieced together there as well.
The structure that we have here is fairly simple for the sake of demonstration. We have:
- A ItemType category e.g. "Food"
- Which has one or more Item e.g. "1 x mug of tea or coffee"
- Which has one or more Variant e.g. "1 x mug of tea or coffee with milk, boiling only what you need"
- Which has one or more Item e.g. "1 x mug of tea or coffee"
Each Variant is tagged with an approximate cost in carbon dioxide equivalent (CO2e) which is essentially a shorthand for expressing all of the greenhouse gases that an activity or item emits in terms of the equivalent amount of carbon dioxide. This loses some accuracy but makes it slightly easier to make comparisons!
You might be surprised to see how much larger the impact is of flying in international fruit out-of-season versus buying locally, I certainly was. I knew there would be an increase of some percentage given the air freight, storage and even the heating and irrigation equipment involved in growing fruit out of season, but approximately twelve times the impact is hard to swallow, and means that I will be checking my purchases much more closely!
Setting up custom data and classes
The three classes we have that construct the above structure look a little like the following: (these have been abbreviated, but you can see the full structures at the repo or in the full gist)
public class ItemType
{
public int Id { get; set; }
public string Name { get; set; }
}
public class Item
{
public int Id { get; set; }
public string ItemName { get; set; }
public double MinCarbonDioxideEquivalent { get; set; }
public double MaxCarbonDioxideEquivalent { get; set; }
}
public class Variant
{
public int Id { get; set; }
public string VariantName { get; set; }
public double CarbonDioxideEquivalent { get; set; }
}This is the data that we want to able to access through GraphQL, so now we need to look at the steps that will allow that to happen.
- GraphQL essentially works using a data "shape", so the first step is to set up graph types that will inform the application what our data structure looks like
- The second paradigm of GraphQL is the query capacity, so we also need to tell the application what queries can be completed and how these queries should work
- Finally, we will need to extend on the work completed by Rasmus and Offroadcode to surface our structure alongside the existing Umbraco content query structure
Let's explore these in more detail...
1. Add new graph types and set our data shape
We'll start with the simplest of our data classes - the ItemType (or parent category)
public class CarbonFootprintCategoryGraphType : ObjectGraphType<ItemType>
{
public CarbonFootprintCategoryGraphType()
{
Name = "CarbonFootprintCategory";
Field<NonNullGraphType<IntGraphType>>(
"id",
resolve: context => context.Source.Id
);
Field<NonNullGraphType<StringGraphType>>(
"name",
resolve: context => context.Source.Name
);
Field<NonNullGraphType<ListGraphType<CarbonFootprintItemGraphType>>>(
"items",
resolve: context => ApplicationContext.Current.DatabaseContext.GetItemsByCategoryId(context.Source.Id)
);
}
}So there are a few things going on here:
- We are inheriting an ObjectGraphType of our data class and this is used as the context.Source when mapping from the properties to the built in GraphQL Schema Types
- We are declaring an "items" property that returns a ListGraphType (a list) of CarbonFootprintItemGraphType objects. This is the next graph type that we will need to define.
The CarbonFootprintItemGraphType looks like this:
public class CarbonFootprintItemGraphType: ObjectGraphType<Item>
{
public CarbonFootprintItemGraphType()
{
Name = "CarbonFootprintItem";
Field<NonNullGraphType<IntGraphType>>(
"id",
resolve: context => context.Source.Id
);
Field<NonNullGraphType<StringGraphType>>(
"name",
resolve: context => context.Source.ItemName
);
Field<NonNullGraphType<CarbonFootprintCategoryGraphType>>(
"category",
resolve: context => ApplicationContext.Current.DatabaseContext.GetCategoryById(context.Source.ItemType)
);
Field<NonNullGraphType<FloatGraphType>>(
"minCarbonDioxideEquivalentInGrams",
resolve: context => context.Source.MinCarbonDioxideEquivalent
);
Field<FloatGraphType>(
"maxCarbonDioxideEquivalentInGrams",
resolve: context => context.Source.MaxCarbonDioxideEquivalent
);
Field<NonNullGraphType<ListGraphType<CarbonFootprintVariantGraphType>>>(
"variants",
resolve: context => ApplicationContext.Current.DatabaseContext.GetVariantsByItemId(context.Source.Id)
);
}
}Again, we are telling GraphQL what our data looks like and how we expect it to be mapped. For reference, the final CarbonFootprintVariantGraphType can be found in this gist.
2. Add new query structures
Now that we have our graph shapes, we need to tell GraphQL how we want to access this data. As an example we are going to expose two query types: byId which gets an ItemType category by its ID and byCategoryName which retrieves an ItemType category by name.
public class CarbonFootprintQueryGraphType : ObjectGraphType
{
public CarbonFootprintQueryGraphType(IEnumerable<IGraphType> carbonFootprintTypes)
{
Name = "CarbonFootprintQuery";
Field<NonNullGraphType<CarbonFootprintCategoryGraphType>>()
.Name("byId")
.Argument<NonNullGraphType<IdGraphType>>("id", "The category id")
.Resolve(context =>
{
var userContext = (UmbracoGraphQLContext)context.UserContext;
var id = context.GetArgument<int>("id");
return userContext.DatabaseContext.GetCategoryById(id);
});
Field<NonNullGraphType<CarbonFootprintCategoryGraphType>>()
.Name("byCategoryName")
.Argument<NonNullGraphType<StringGraphType>>("category", "The category name")
.Resolve(context =>
{
var userContext = (UmbracoGraphQLContext)context.UserContext;
var name = context.GetArgument<string>("category");
return userContext.DatabaseContext.GetCategoryByName(name);
});
}
}Here we are defining the argument types that we will accept such as, for example, category which is non-nullable and of type StringGraphType.
To resolve our item data mapping we are resolving an ItemType of the user-defined category, and this is linking to our previously constructed CarbonFootprintCategoryGraphType
We now want to extend the existing UmbracoQuery ObjectGraphType to accept our custom CarbonFootprintQueryGraphType
public class UmbracoQuery : ObjectGraphType
{
public UmbracoQuery(IEnumerable<IGraphType> documentTypes, IEnumerable<IGraphType> carbonFootprintingData)
{
Field<PublishedContentQueryGraphType>()
.Name("content")
.Resolve(context => context.ReturnType)
.Type(new NonNullGraphType(new PublishedContentQueryGraphType(documentTypes)));
Field<CarbonFootprintQueryGraphType>()
.Name("carbonFootprintItems")
.Resolve(context => context.ReturnType)
.Type(new NonNullGraphType(new CarbonFootprintQueryGraphType(carbonFootprintingData)));
}
}There is a magic IEnumerable<IGraphType> carbonFootprintingData parameter being passed into the query here - we will get onto where that comes from in just a bit.
This data "shape" allows us to make queries that are in some variation of the following structure:
{
carbonFootprintItems {
byCategoryName(category: "food") {
name
items {
name
variants {
name
carbonDioxideEquivalentInGrams
}
}
}
}
}3. Extend existing schema
So now we have our data shape and matching query, the final step is to extend the existing Our.Umbraco.GraphQL package to also serve our data alongside the built-in Umbraco content. To do this, we will need to dig into the UmbracoSchema class in order to register our custom schema.
public class UmbracoSchema : global::GraphQL.Types.Schema
{
public UmbracoSchema(
IContentTypeService contentTypeService, IMemberTypeService memberTypeService,
DatabaseContext dbContext, GraphQLServerOptions options)
{
// These are the Umbraco content schema graph types
var documentTypes = CreateGraphTypes(contentTypeService.GetAllContentTypes(), PublishedItemType.Content).ToList();
var mediaTypes = CreateGraphTypes(contentTypeService.GetAllMediaTypes(), PublishedItemType.Media).ToList();
RegisterTypes(documentTypes.ToArray());
RegisterTypes(mediaTypes.ToArray());
// Custom data schema graph types!
var carbonFootprintTypes = new List<IGraphType>();
var categories = dbContext.GetAllCategories();
foreach (var category in categories)
{
graphTypes.Add(new CarbonFootprintGraphTypeMap(dbContext, category));
}
// Register our graph types with GraphQL
RegisterTypes(carbonFootprintTypes.ToArray());
Query = new UmbracoQuery(documentTypes, carbonFootprintTypes);
}
}We are looping through all of our data categories and using them to create the IEnumerable<IGraphType> carbonFootprintingData argument that was referenced in the earlier snippet.
Now, if we navigate to our [localhost url]/umbraco/graphiql we can run the query:
{
carbonFootprintItems {
byCategoryName(category: "activities") {
name
items {
name
maxCarbonDioxideEquivalentInGrams
variants {
name
carbonDioxideEquivalentInGrams
}
}
}
}
}And receive a corresponding result:
{
"data": {
"carbonFootprintItems": {
"byCategoryName": {
"name": "Activities",
"items": [
{
"name": "1 x shower",
"maxCarbonDioxideEquivalentInGrams": 1700,
"variants": [
{
"name": "3 minute shower / efficient gas boiler, aerated shower head",
"carbonDioxideEquivalentInGrams": 90
},
{
"name": "6 minute shower / typical electric shower",
"carbonDioxideEquivalentInGrams": 500
},
{
"name": "15 minute shower / 11-kilowatt electric power shower",
"carbonDioxideEquivalentInGrams": 1700
}
]
},
{
"name": "Spending £1",
"maxCarbonDioxideEquivalentInGrams": 10000,
"variants": [
{
"name": "Spending £1 on a well-executed rainforest preservation project",
"carbonDioxideEquivalentInGrams": -330000
},
{
"name": "Spending £1 on solar panels",
"carbonDioxideEquivalentInGrams": -3000
},
{
"name": "Spending £1 on financial, legal or professional advice",
"carbonDioxideEquivalentInGrams": 160
},
{
"name": "Spending £1 on a car",
"carbonDioxideEquivalentInGrams": 720
},
{
"name": "Spending £1 on a typical supermarket trolley of food",
"carbonDioxideEquivalentInGrams": 930
},
{
"name": "Spending £1 on petrol for your car",
"carbonDioxideEquivalentInGrams": 1700
},
{
"name": "Spending £1 on flights",
"carbonDioxideEquivalentInGrams": 4600
},
{
"name": "Spending £1 on the electricity bill",
"carbonDioxideEquivalentInGrams": 6000
},
{
"name": "Spending £1 on budget flights",
"carbonDioxideEquivalentInGrams": 10000
}
]
}
]
}
}
}Now if you had a decoupled front-end app, you could see how the GraphQL endpoint could be used to return this data alongside any Umbraco content by writing the queries directly from the client-side!
We hear a lot about limiting the global temperature increase to 1.5 degrees, and this means that by 2050 the goal is for each of us to have carbon dioxide equivalent (CO2e) emissions that do not exceed 2.1 tonnes annually. To put this in current perspective, the average UK person has an annual footprint of around 15 tonnes. In China and Malawi this number is less, but in America and Australia this number is more.
The ability to improve one's lifestyle to this degree will require substantial changes, but not all at once. It's like any project that you work on, you need to know what you're working with and where there is legacy and inefficient code that can be refactored for new habits to be built on top. Getting informed is the best first step to making intelligent choices.
In conclusion
Hopefully, this has given you a starting point for how your own data structures could be resolved alongside the Umbraco content and adds another option that you might consider when scoping out new projects. GraphQL is just a tool and will not be suitable for every project or use case, but for sites that have large amounts of structured, related data it should increasingly be a consideration. As previously mentioned you can see all gists here or fork the branch for this demo here.
Next steps for this implementation, and sadly outside the scope of this article for now, include:
- sorting and filtering our custom data
- pagination of data lists
- securing our queries and permissions
I also hope that some of the data I have surfaced in my demo has given you pause for thought, as it has done me. The climate change data and approximate costs of these products and activities are taken from the excellent book by Mike Berners-Lee (@MikeBernersLee), "How bad are bananas? The carbon footprint of everything", and have had a profound influence on how I approach being a consumer. If you want to find out more, he has a number of insightful (and quite terrifying) books on the subject matter.
Thanks for following along, I hope it has been interesting! I will leave you with some words from Greta Thunberg:
"Yes, we need a system change rather than individual change. But you cannot have one without the other.
"If you look through history, all the big changes in society have been started by people at the grassroots level. People like you and me."
- Greta Thunberg