
One evening while sitting on my computer, I was speaking with Nik Rimington about what side projects he had on and how we were both starting to migrate our individual blogs over to Umbraco 8 from Umbraco 7.
We started talking about how we plan to migrate our blogs from one site to the other, one option was obvious, we could use Umbraco's migration method, bring over all the data, upgrade the database and we could be up and running pretty quickly. I was about to do that but then I decided that I actually want to get my Umbraco site running as native as I can. What do I mean by this?
My blog, Owain.Codes, currently runs on Umbraco 7 with the uSkinned package installed. I've really enjoyed working with the uSkinned template and backoffice setup but I've decided I want to tinker with Umbraco backoffice a bit more on my own. Build packages and install them on my own setup and see how they work on a clean Umbraco 8 site. With this in mind, I don't want to migrate all the document types, templates, property editors etc. that are part of uSkinned.
Nik and I discussed some other options and that was when we came up with a side project for me to start. The Blog to Markdown parser project. I wrote down some features that might be nice to try and build and with a little bit of thought, I started to investigate ways I could migrate all my blogs from my Umbraco 7 site.
I booted up Visual Studio and created a blank console application and got to work. Then I stopped. I then loaded up notepad and wrote out what I was trying to accomplish. I'm pretty bad at loading up Visual Studio and then going off on a crazy journey of unfocused coding. I usually then get annoyed, disheartened and give up. I have so many projects that have been started and never completed. I was determined that this project was not going to be one of them. In notepad, I wrote the following list of tasks.
* Make the project open source.
* Get a list of all the blogs.
* Read all the blogs and save them locally in markdown format.
* Copy of all the images attached to each blog post.
Now I had a plan, a side project to learn from and something to focus on.
Make the project open source
This was the easy bit. I created a github repo, cloned it to my local environment and created a new C# .Net Framework project in Visual Studio. I then pushed that project up to the repo. The project was initially made private until I was ready but essentially it was now open source for the world to see. As a side note, I have also been learning some of the finer details of Git and trying to use the command line a bit more, but I still revert back to GitKraken when I want to visually see the mess I've made of my repo 🙈
The repository master branch view in Git Kraken
I'm always a bit embarrassed to admit that I use a GUI for Git because I grew up using MS-Dos and should feel more comfortable with command line than I do. Maybe it's just Git that confuses me rather than the actually command? Anyway, back to the project!
✏ Get a list of all the blogs
In my head, this started out as a super complicated thing to do. The reason it was super complicated is simple, I was over thinking things! No surprise there. My thought process went something like this:
- Load up the blog section of my website
- Crawl the page for links, follow the links
- If the link lands on a page that is within my domain check to see if it's part of the blog section
- Over think things a bit more
- Over think things even more
- Job done! 😵
You see where I was going with this?
Then I sat back, walked away from my laptop and rethought about what I was trying to do. What do I need? I need a list of links for all my blogs. Something like an RSS feed for my blogs.
⏰ Wait a minute!
I have an RSS feed for all the blog posts on my site!
My thought process was now a lot simpler and I chopped my tasks in to smaller, more manageable tasks. The first task was to successfully hit the RSS feed and get the first link. If I could get one link, then I should be able to get all the links. Start small and work up from there.
public async Task<List<string>> GetFeedLinksAsync()
{
List<string> links = new List<string>();
var readerTask = await FeedReader.ReadAsync(FeedUrl);
// Get the link from the RSS feed, remove trailing edges and remove any mess e.g. new lines
// Add it to a list.
foreach (var item in readerTask.Items)
{
string link = item.Link.ToString();
DateTime? pubDate = item.PublishingDate;
string publishedDate = pubDate.Value.ToString("dd-MM-yyyy");
links.AddMany(CleanupLink(link), publishedDate);
}
return links;
}
public string CleanupLink(string item)
{
var cleanedUpLink = item.Trim().Replace(@"\t|\n|\r", "");
return cleanedUpLink;
}
I created a list of links and also did a secondary task of cleaning up some of the links as I found I was getting some strange characters in my feed which would then break the download later on.
📝 Save an HTML blog to Markdown
Now that I had a list of links, it was time to get the HTML and convert it to Markdown. A couple of nights before I was at this stage, I had been sitting up in bed, unable to sleep and I was looking at options to convert HTML to Markdown and I stumbled upon a package called Reverse Markdown and it did exactly what I needed. It takes an HTML input and converts it to Markdown.
As a proof of concept, I started saving each blog individually as blog1.md, blog2.md, blog3.md etc. The Markdown was perfect and within the config section I was able to configure it a bit too so that it ignores comments, removes markdown output for links and uses the GitHub flavour of markdown so I can still have tables etc.
Once I was finished with this initial build, I released the code in to the wild, made my GitHub repo public and invited collaborators.
What happened next I didn't expect.
🙀 It's in the wild
A couple of days after announcing my side project, I received an email saying there had been a pull request created. My heart sank, had I totally messed something up?
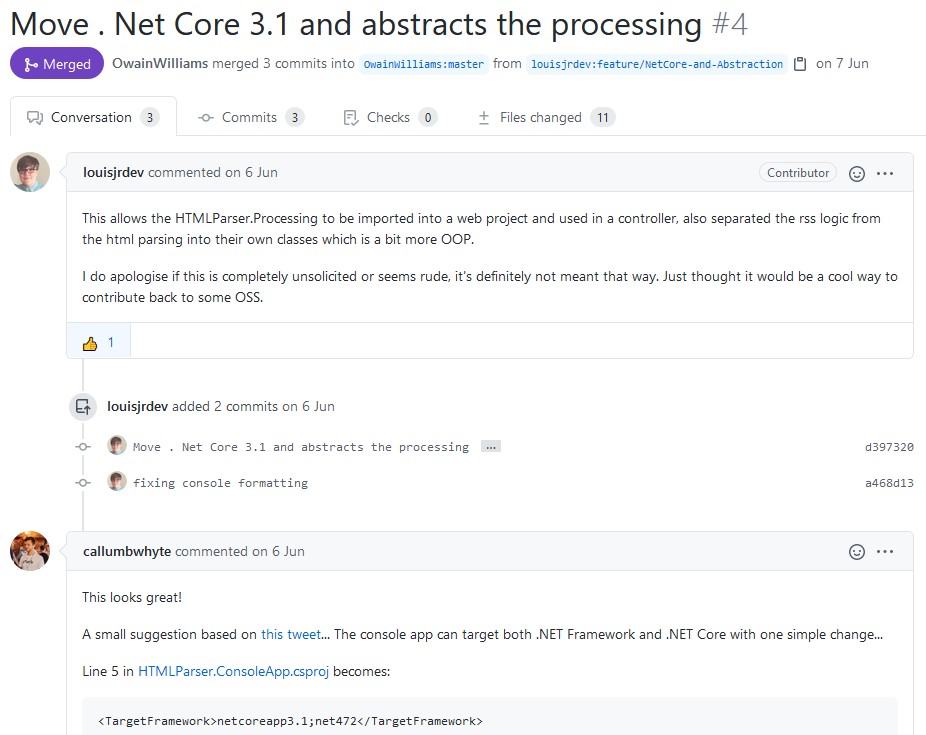
Pull request for a .NET Core conversion of the progress
I opened up the pull request and I saw that Louis had converted the project to run in .Net Core! Amazing and such a great idea. What I loved most about this PR was the fact he was so apologetic about taking my code and reworking it. This was exactly why I published this project and asked for pull requests. I wanted others to play with it, improve it and in the process I would also learn from it.
I then had another comment added to the project by Callum and he suggested a way to run the code as .Net Framework and .Net Core at the same time. #h5yr to both of you!
✨ Make improvements
Naming
I now had a .Net Core console app that could read my RSS Feed and make the blogs in to Markdown but I was really enjoying learning new skills and so I continued to make improvements.
I installed HTMLAgilityPack so that I could read the HTML and get the title of each blog and also the published date. With this information I could then create a folder for each blog and title it meaningfully.
With this information, I also saved the Markdown file with the title of the blog.
Error logging
Rather than outputting all my error logging to the console I installed Serilog. This was another learning experience and it was good to get logging setup and this also meant that this project could be ran outwith a console app. Serilog allows for logging in any environment that I run this code in. It also meant I could log things in different ways, is it just information, is it an actual error. It was much easier to look at the text file that had all the logs in it than have to run the application each time to then catch an output in the window.
Unit testing
Every time I made a change, the only way I could test it worked was by running the code against my blog. This was becoming time consuming, especially if I knew the converter had issues after reading 20 blogs. I would need to run the code, wait for the 20th blog and then see if my fix worked.
This was time consuming and so I started to investigate setting up some tests. I've never created or ran unit tests for my code so this was really interesting. It made me really think about how I structured my code and how I code test small, specific sections.
[TestMethod]
public void Remove_Whitespace_From_End_Url()
{
// Arrange
string url = "https://owain.codes/something ";
string expected = "https://owain.codes/something"; // Act
RssFeedProcessor test = new RssFeedProcessor(url); // Assert
string actual = test.CleanupLink(url);
Assert.AreEqual(expected, actual, "URL hasn't been cleaned up");
}This single test just checks that the whitespace at the end of a url is removed.
Resize images
When I was downloading the blogs and then downloading all the images for the blogs I noticed a number of images were really big downloads.
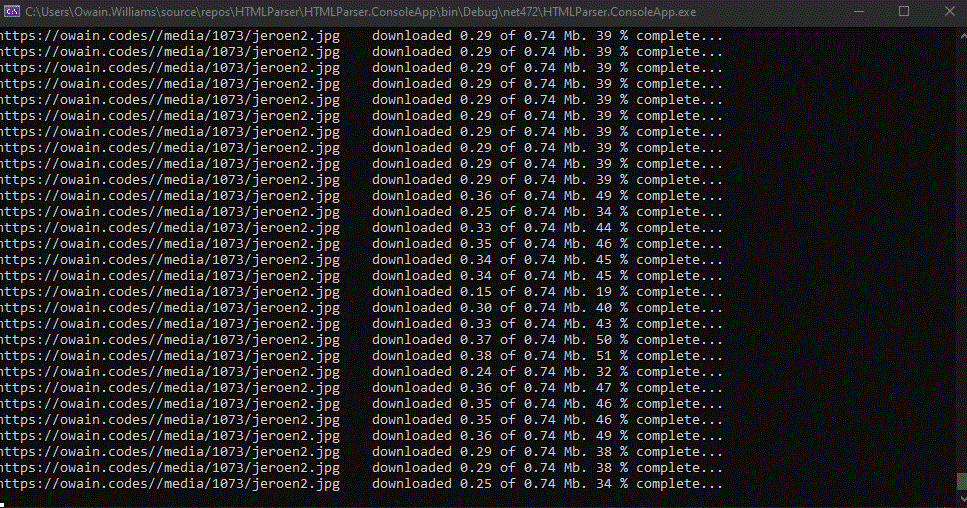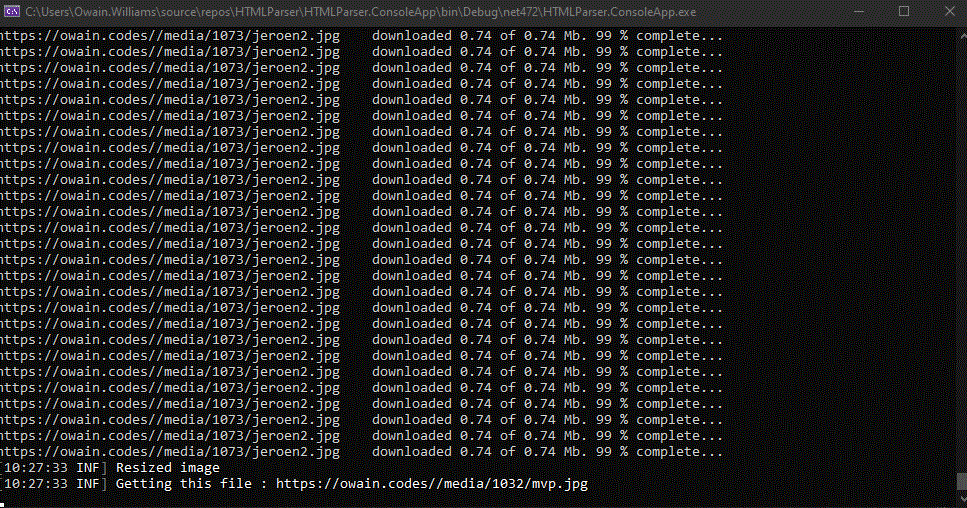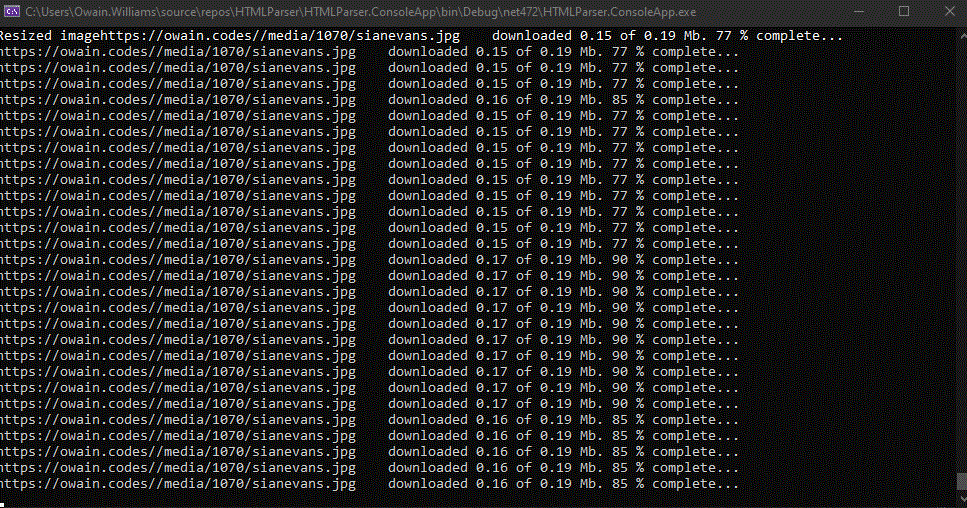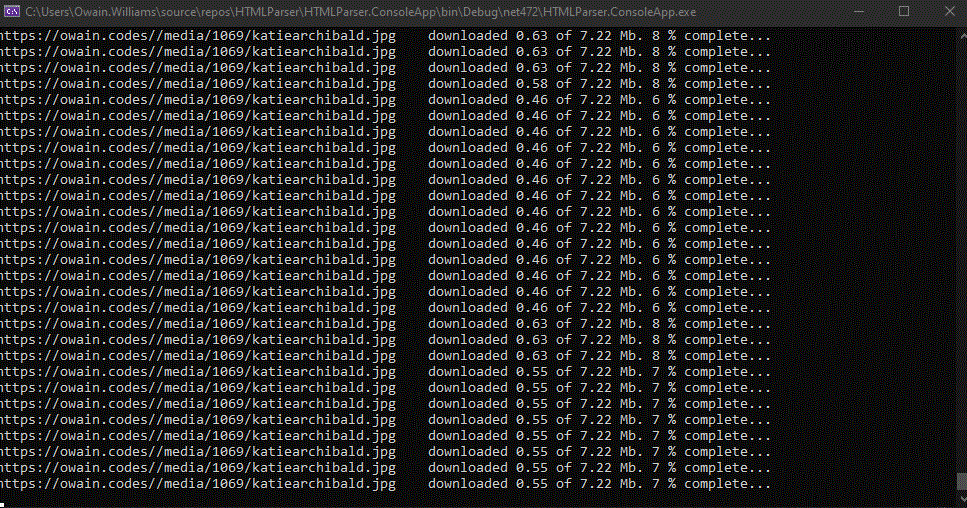
The media downloading in command line
A 7Mb image is not something that should be on a blog! I feel sorry for anyone that might have read that blog on their mobile phone!
I really didn't want to migrate these to the new blog. I could manually go through each folder, resize the images and then use them on my new blog but why do it manually when I could do it via my application. I started looking at ways to resize the images when saving them. ImageSharp to the rescue!
All I had to do was install the package and before saving the image to disk, resize the image with a given width variable. This resizes all the images to a specific width and keeps the aspect ratio. If I set the width and height, it would force all images to that size which I didn't want. The 7Mb image that had been on my blog is now 172Kb!
What I did do was I ended up saving all the original images and then saving the resized versions in a separate folder, just so I have both, the original and the resized image. This was more so I have a backup and if any of the images could do with being a bit larger than I can still manually change that specific image. Either way, it's still faster than resizing every image manually!
using (Image image = Image.Load(outputDirectory+"\\"+filePath))
{
image.Mutate(x => x
.Resize(300, 0));
string fileName = Path.GetFileNameWithoutExtension(filePath);
image.Save(outputDirectory+"\\resized\\"+fileName+".jpg"); // Automatic encoder selected based on extension.
}
I was really impressed with this package. So much work has gone in to it. I hope to be able to give back to the project at some point as I know James is looking for collaborators for the project.
Done!
The aim was to get all my blogs out of my current Umbraco 7 website and convert each blog to Markdown. That has been accomplished and on the way I've learnt a load of new skills. I learned that using pre-built packages isn't cheating and you don't need to always do everything on your own, for example, to do the amount of work that ImageSharp does, on my own, that would be almost impossible then add in the Markdown converter and the error logging, I would never get this project finished!
I would highly recommend anyone to have at least one side project going and don't give up when things get hard. As I said at the start of this article, I have so many projects I stopped because it got difficult. Instead of giving up, ask for help. Post on twitter, join slack communities, post on forums, do whatever you need to but don't give up. You don't learn anything by giving up other than how to give up.
💭 Thoughts for the future?
This project has grown from a just getting the blogs from my website and I've loved it. I've had a suggestion for an improvement and it's to upload all the Markdown to a private Git repo on save. It's on my todo list as this will help me learn more about Git and also how to script the application to do this for me.
One thing that I haven't looked at yet though is actually getting the Markdown files and images in to my Umbraco 8 site, that may be another article for the future!
If you have any other ideas on how to improve this project, please feel free to open a suggestion on the repo.
....and finally, Thank you!
Thanks to Nik, Louis, Callum and everyone else from the Umbraco Community that has contributed in some way, whether it's replying to a tweet or posting a comment on the repo. To all of you, #H5YR!